
티스토리 뷰
머신러닝 카테고리의 두 번째 글에서는 머신러닝의 분류와 머신러닝 알고리즘을 모델링할 때 고려해야 하는 과적합에 대해 다뤄보겠습니다.
이 글의 목차는 다음과 같습니다.
- 지도학습
- 비지도학습
- Overfitting과 Underfitting
1. 지도학습
머신러닝의 분류에서 첫 번째로 다룰 항목은 지도학습(Supervised Learning)입니다. 이전 글에서 머신러닝에서 가장 중요한 것은 data에 맞는 함수를 만들고 실제값에 근접한 예측값을 추출하는 것이라 언급하였습니다. 머신러닝은 data의 성질에 따라 각각 적절한 함수(모델)가 분류되어 있습니다. 먼저 지도학습 알고리즘은 분석에 사용되는 data 내에 label이라는 정답이 존재할 때 사용됩니다. 지도학습의 목적은 새로운 data의 label을 분류하거나 예측하기 위해 data의 label을 학습하는 것입니다. 예를 들어, 개와 고양이를 분류하는 알고리즘을 구현하고자 할 때, 지도학습은 개와 고양이를 나타내는 label을 학습하여 새로운 data의 label이 개인지 고양이인지 예측하는 것입니다. 예시와 같이 지도학습의 대표적인 알고리즘은 분류와 회귀 알고리즘이 있습니다.

2. 비지도학습
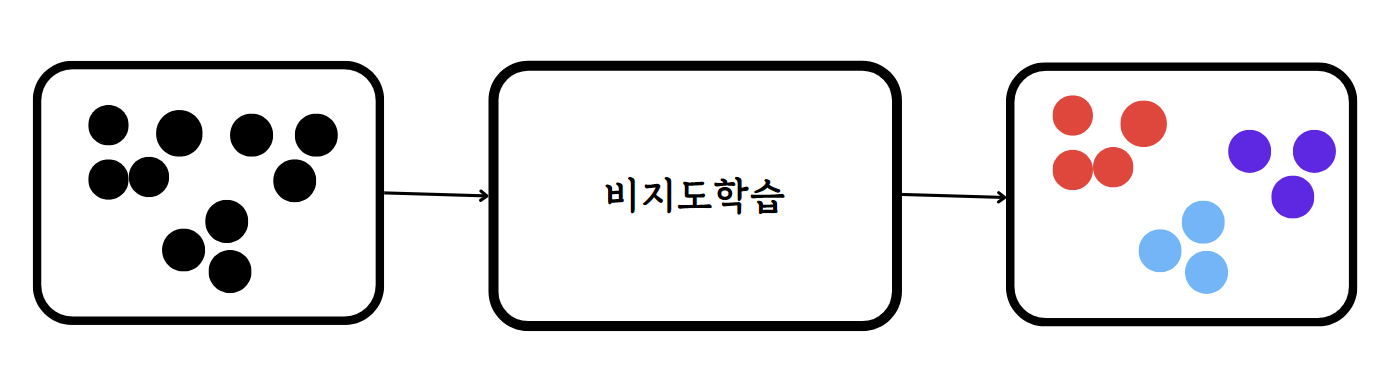
비지도학습(Unsuperviesed Learning)은 지도학습과 다르게 label이 존재하지 않는 data를 다루는 알고리즘입니다. 결국 data가 가지고 있는 특성 자체를 학습하여 새로운 data의 특성은 어떠한지 추출하는 것이 비지도학습의 목적입니다. label, 즉 정답이 없는 data를 학습하는 비지도학습이기에 지도학습보다 높은 정확도를 만들어내는데 어려움이 있지만 data의 특징을 추출할 때 유용하게 사용됩니다. 예를 들어 label이 없는 data를 비슷한 특성끼리 묶는 군집화를 하고 싶을 때 비지도학습이 사용됩니다. 비지도학습 예에는 KMeans 알고리즘이나 PCA 주성분 분석이 있습니다.
3. Overfitting과 Underfitting
지금까지 이전 글을 포함하여 머신러닝의 개요와 분류에 대해 알아봤습니다. 즉 머신러닝을 활용할 때는 data의 성질을 파악해 모델을 구현하는 것이 핵심입니다. Overfitting과 Underfitting은 모델을 구현할 때 가장 고려해야 하는 2가지입니다.

먼저 Underfitting에 대해 알아보겠습니다. Underfitting에 대해 한 문장으로 표현하자면, 데이터 복잡도에 비해 모델 복잡도가 떨어져 학습 정확도가 매우 낮다라는 것입니다. 여기서 복잡도는 표현하는 정도라고 이해하시면 좋습니다. 즉 우리가 구현한 모델의 표현하는 정도가 데이터가 표현하는 정도를 따라가지 못해 데이터의 패턴을 모델이 제대로 학습하지 못하여 정확도가 매우 낮다는 것입니다. 위 그림에서와 같이 복잡도가 낮은 일차방정식의 모델이 data를 표현하기에는 큰 어려움이 있다는 것을 알 수 있습니다. 이를 방지하기 위해서는 data의 양을 증가시키거나 학습 반복 횟수를 늘리는 것입니다.
Overfitting은 Undefitting과 달리 모델 복잡도가 매우 커 학습해야 하는 파라미터의 수가 매우 많은 상태를 의미합니다. 우리가 구현한 모델 F(x)의 파라미터 수가 매우 많다면 데이터가 표현하는 정도를 모델이 넘어서기 때문에 시간도 매우 오래 걸리는 문제가 발생합니다. 이런 상태는 학습 정확도는 높을 수 있지만 새로운 data를 예측하는 정확도는 매우 떨어지는 결과를 도출합니다. 학습 정확도가 높은 것은 머신러닝의 일차적인 목표는 이뤘다고 볼 수 있지만 정확도 낮은 예측값을 도출하기에 Overfitting은 반드시 해결해야 하는 문제입니다. Overfitting을 해결할 수 있는 방법은 구현한 모델의 파라미터 수를 줄여 단순하게 만드는 것이 가장 중요합니다. Occam's Razor라고 '수많은 모델 중 가장 정확도가 높은 모델은 가장 단순한 모델이다'라는 말처럼 머신러닝의 목적은 가장 정확도가 높고 단순한 모델을 구현하여 데이터의 패턴을 정확하게 매칭시키는 것입니다.
'머신러닝' 카테고리의 다른 글
| [5] KMeans 알고리즘 (0) | 2024.05.15 |
|---|---|
| [4] Support Vector Machine(SVM) (0) | 2024.05.12 |
| [3] K 근접 이웃 알고리즘(knn) (0) | 2024.05.10 |
| [2] 선형회귀 (0) | 2024.05.05 |
| [0] 머신러닝이란? (1) | 2024.05.01 |
- #opencv #이미지 연산 #합성
- #자연어 처리 #정수 인코딩 #빈도 수 기반
- #seq2seq #encoder #decoder #teacher forcing
- # 할인행사 #counter #딕셔너리 #프로그래머스
- #docker #image #build #dockerfile
- nlp #토큰화 #nltk #konply
- #python #프로그래머스 #외계어사전 #itertools #순열과조합
- # 프로그래머스 #연속된 부분수열의 합 #이중 포인터 #누적합
- #polars #대용량 데이터셋 처리
- 잘라서 배열로 저장하기 #2차원으로 만들기
- #attention #deeplearning
- 머신러닝 #lightgbm #goss #ebf
- 머신러닝 #project #classification #dacon
- 로지스틱 회귀 #오즈비 #최대우도추정법 #머신러닝
- python #프로그래머스 #겹치는선분의길이
- #django #mvt 패턴
- #docker #docker compose
- #docker #container #docker command
- #웹 프로그래밍 #서버 #클라이언트 #http #was
- #물고기 종류별 대어 찾기 #즐겨찾기가 가장 많은 식당 정보 출력하기 #mysql #programmers
- #프로그래머스 #안전지대 #시뮬레이션
- randomforest #bagging #머신러닝 #하이퍼파라미터 튜닝
- 자연어 처리 #정제 #정규표현식 #어간 추출 #표제어 추출
- #opencv #이미지 읽기 #이미지 제작 #관심영역 지정 #스레시홀딩
- 프로젝트 #머신러닝 #regression #eda #preprocessing #modeling
- #tf idf
- #with recursive #입양시각 구하기(2) #mysql
- # 프로그래머스 # 카펫 # 완전탐색
- 머신러닝 #xgboost #
- pca #주성분분석 #특이값분해 #고유값분해 #공분산행렬 #차원의 저주