
티스토리 뷰
분류 머신러닝 모델링에서 중요한 점은 종속 변수가 수치형이어야 하는 점입니다. 오늘 포스트 할 의사결정나무(Decision Tree Model)은 종속 변수가 범주형일 경우, 수치형일 경우 모두 사용할 수 있는 분류 지도학습 알고리즘입니다. 예를 들어, 고객의 OOT 서비스의 리뷰에 따라 재구독 여부를 분류하고자 할 때 종속 변수인 "재구독"과 "해지"가 범주형 데이터인 경우 의사결정나무를 통해 분류할 수 있습니다.
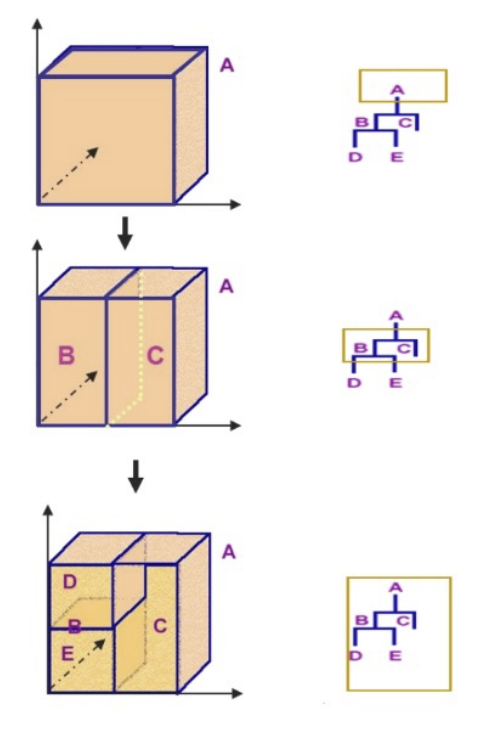
의사결정나무 모델은 데이터에 내재되어 있는 패턴을 분석해 예측 분류 모델을 나무의 형태로 만드는 것입니다. 전체 데이터가 특정 조건에 의해 이진 분할로 부분집합 형태로 나누어지고 더 이상 분류할 수 없을 때까지 과정을 반복하는 것입니다.
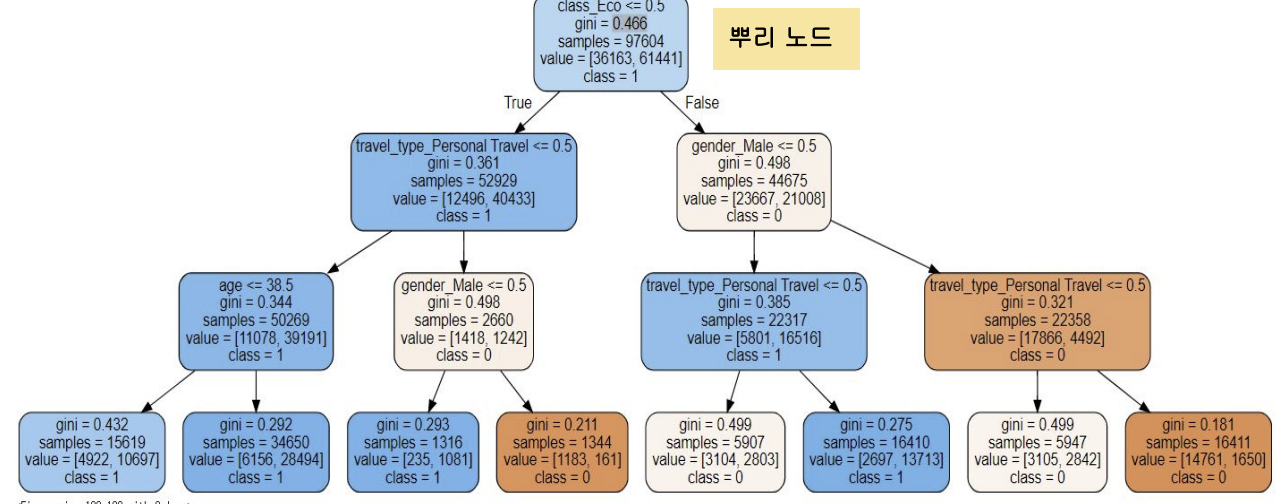
의사결정 나무 모델링에서 가장 먼저 이뤄지는 단계는 독립 변수를 이용해 패턴을 만들어 가는 것입니다. 패턴을 만들기 위해 나무의 형태 중 가지와 잎 노드의 수를 정해야 합니다. 가지와 잎 노드는 의사결정나무 모델의 구성 요소입니다. 가지는 각 노드와 노드를 연결하는 것이고 잎 노드는 끝마디라고도 하며, 잎 노드의 개수만큼 패턴을 생성합니다.
결국 의사결정나무에서 가지 분할 기준에 따라 가지의 개수를 정하는 것이 가장 중요합니다. 크게 가지 분할 기준은 카이제곱 통계량, 지니 계수, 엔트로피 지수가 있습니다. 위 분할 기준은 분류된 패턴 내에 서로 다른 특성을 가진 데이터가 섞여 있는 불순도를 줄이는 방향으로 수치가 나오는 것이 최적입니다.
카이제곱 통계량은 데이터의 분포와 개발자가 선택한 기대 또는 가정된 분포 사이의 차이를 나타내는 측정값입니다. 종속 변수에 대해 독립 변수에 따라 분류한 후 통계량이 더 큰 분류 기준으로 종속 변수를 분류해야 합니다. 다음의 예시에서 카이제곱 통계량이 결혼 유무보다 성별이 더 크므로 종속변수인 LC와 CC는 성별로 분류되어야 불순도를 감소시킬 수 있는 것입니다.

| LC | CC | 합계 | |
| 남 | 5 | 1 | 6 |
| 여 | 0 | 4 | 4 |
| 합계 | 5 | 5 | 10 |

| LC | CC | 합 | |
| 기혼 | 2 | 3 | 5 |
| 미혼 | 3 | 2 | 5 |
| 합계 | 5 | 5 | 10 |

지니 계수(Gini index)는 노드의 불순도를 나타내는 값이며 값이 클수록 서로 다른 특성을 가진 데이터가 많이 섞여 있다는 것을 알 수 있습니다. 지니 계수는 각 클래스(비슷한 특성을 가진 데이터가 모인 범주)의 제곱들의 합을 구해야 합니다.

엔트로피 지수는 불확실성을 보여주는 지표로 사용됩니다. 지수 값이 1에 가까울수록 불확실성이 크고 분류가 잘 되지 않았다는 것을 의미합니다. 의사결정나무에서 가지치기를 통해 분류를 하기 전과 후의 엔트로피 지수를 비교하면서 분류의 확실성을 크게 하는 것이 중요합니다. 다음의 예시에서 엔트로피 구하는 공식을 이용하면 부분 집합으로 분할하기 전의 엔트로피를 구하면 1에 매우 가까운 0.95의 값이 나옵니다.


만약 위의 예시를 다음과 같이 분할한다면 분할 후에 특정 영역에 속하는 데이터의 비율을 구해 새로운 엔트로피를 구할 수 있습니다. 새로운 엔트로피가 분할 전의 엔트로피보다 작음을 알 수 있습니다. 이를 통해 의사결정나무 모델은 분할 기준에 따라 가지를 쳐서 전체 데이터를 부분 집합화하는 것이 불확실성을 낮추고 분류 성능을 높일 수 있다는 것을 알 수 있습니다.


'머신러닝' 카테고리의 다른 글
| [10] 로지스틱 회귀 모델 (1) | 2025.02.11 |
|---|---|
| [9] 정규화 모델 (Regularization) (0) | 2024.07.07 |
| [7] 앙상블 모델 (0) | 2024.06.28 |
| [6] 주성분 분석(PCA) (0) | 2024.05.17 |
| [5] KMeans 알고리즘 (0) | 2024.05.15 |
- 머신러닝 #lightgbm #goss #ebf
- # 프로그래머스 #연속된 부분수열의 합 #이중 포인터 #누적합
- 로지스틱 회귀 #오즈비 #최대우도추정법 #머신러닝
- #프로그래머스 #안전지대 #시뮬레이션
- #물고기 종류별 대어 찾기 #즐겨찾기가 가장 많은 식당 정보 출력하기 #mysql #programmers
- #opencv #이미지 읽기 #이미지 제작 #관심영역 지정 #스레시홀딩
- # 할인행사 #counter #딕셔너리 #프로그래머스
- #opencv #이미지 연산 #합성
- nlp #토큰화 #nltk #konply
- #django #mvt 패턴
- #docker #image #build #dockerfile
- pca #주성분분석 #특이값분해 #고유값분해 #공분산행렬 #차원의 저주
- 머신러닝 #xgboost #
- #자연어 처리 #정수 인코딩 #빈도 수 기반
- #attention #deeplearning
- #seq2seq #encoder #decoder #teacher forcing
- 자연어 처리 #정제 #정규표현식 #어간 추출 #표제어 추출
- #python #프로그래머스 #외계어사전 #itertools #순열과조합
- #웹 프로그래밍 #서버 #클라이언트 #http #was
- 프로젝트 #머신러닝 #regression #eda #preprocessing #modeling
- 잘라서 배열로 저장하기 #2차원으로 만들기
- #with recursive #입양시각 구하기(2) #mysql
- # 프로그래머스 # 카펫 # 완전탐색
- 머신러닝 #project #classification #dacon
- #docker #container #docker command
- python #프로그래머스 #겹치는선분의길이
- #docker #docker compose
- randomforest #bagging #머신러닝 #하이퍼파라미터 튜닝
- #tf idf
- #polars #대용량 데이터셋 처리